
![]()
![]()
Description: This tutorial is an introduction to the FIWARE Cosmos Orion Spark Connector, which enables easier Big Data analysis over context, integrated with one of the most popular BigData platforms: Apache Spark. Apache Spark is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Spark has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
The tutorial uses cUrl commands throughout, but is also available as Postman documentation.

![]()
Real-time Processing and Big Data Analysis
"Don't judge each day by the harvest you reap but by the seeds that you plant."
— Robert Louis Stevenson
Smart solutions based on FIWARE are architecturally designed around microservices. They are therefore are designed to scale-up from simple applications (such as the Supermarket tutorial) through to city-wide installations base on a large array of IoT sensors and other context data providers.
The massive amount of data involved eventually becomes too much for a single machine to analyse, process and store, and therefore the work must be delegated to additional distributed services. These distributed systems form the basis of so-called Big Data Analysis. The distribution of tasks allows developers to be able to extract insights from huge data sets which would be too complex to be dealt with using traditional methods. and uncover hidden patterns and correlations.
As we have seen, context data is core to any Smart Solution, and the Context Broker is able to monitor changes of state and raise subscription events as the context changes. For smaller installations, each subscription event can be processed one-by-one by a single receiving endpoint, however as the system grows, another technique will be required to avoid overwhelming the listener, potentially blocking resources and missing updates.
Apache Spark is an open-source distributed general-purpose cluster-computing framework. It provides an interface for programming entire clusters with implicit data parallelism and fault tolerance. The Cosmos Spark connector allows developers write custom business logic to listen for context data subscription events and then process the flow of the context data. Spark is able to delegate these actions to other workers where they will be acted upon either in sequentially or in parallel as required. The data flow processing itself can be arbitrarily complex.
Obviously, in reality, our existing Supermarket scenario is far too small to require the use of a Big Data solution, but will serve as a basis for demonstrating the type of real-time processing which may be required in a larger solution which is processing a continuous stream of context-data events.
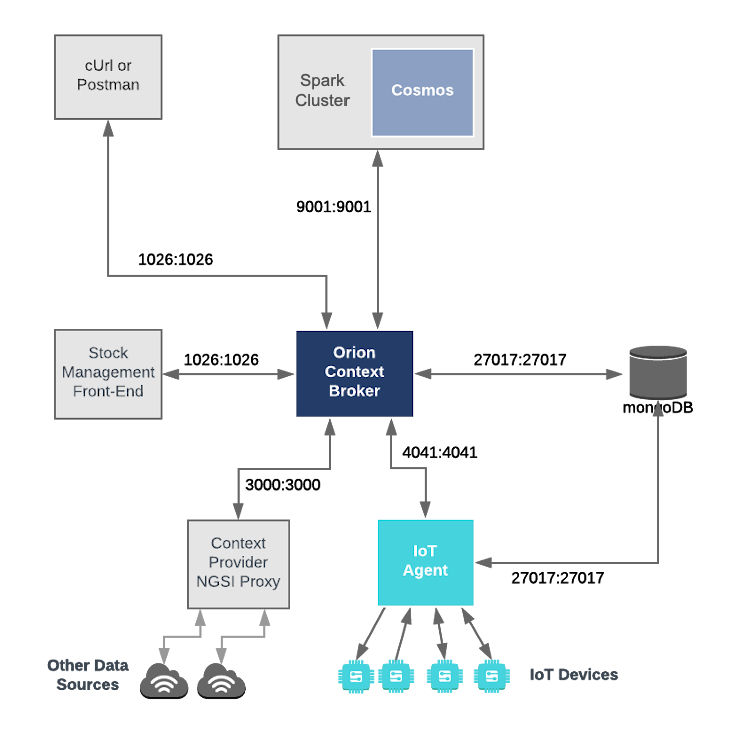
Architecture
This application builds on the components and dummy IoT devices created in previous tutorials. It will make use of three FIWARE components - the Orion Context Broker, the IoT Agent for JSON, and the Cosmos Orion Spark Connector for connecting Orion to an Apache Spark cluster. The Spark cluster itself will consist of a single Cluster Manager master to coordinate execution and some Worker Nodes worker to execute the tasks.
Both the Orion Context Broker and the IoT Agent rely on open source MongoDB technology to keep persistence of the information they hold. We will also be using the dummy IoT devices created in the previous tutorial.
Therefore the overall architecture will consist of the following elements:
- Two FIWARE Generic Enablers as independent microservices:
- The Orion Context Broker which will receive requests using NGSI-LD.
- The FIWARE IoT Agent for JSON which will receive southbound requests using NGSI-LD and convert them to JSON commands for the devices.
- An Apache Spark cluster consisting of a single
ClusterManager and Worker Nodes:
- The FIWARE Cosmos Orion Spark Connector will be deployed as part of the dataflow which will subscribe to context changes and make operations on them in real-time.
- One MongoDB database:
- Used by the Orion Context Broker to hold context data information such as data entities, subscriptions and registrations.
- Used by the IoT Agent to hold device information such as device URLs and Keys.
- An HTTP Web-Server which offers static
@contextfiles defining the context entities within the system. - The Tutorial Application does the following:
- Acts as set of dummy agricultural IoT devices using the JSON.
The overall architecture can be seen below:
Spark Cluster Configuration
spark-master:
image: bde2020/spark-master:2.4.5-hadoop2.7
container_name: spark-master
expose:
- "8080"
- "9001"
ports:
- "8080:8080"
- "7077:7077"
- "9001:9001"
environment:
- INIT_DAEMON_STEP=setup_spark
- "constraint:node==spark-master"
spark-worker-1:
image: bde2020/spark-worker:2.4.5-hadoop2.7
container_name: spark-worker-1
depends_on:
- spark-master
ports:
- "8081:8081"
environment:
- "SPARK_MASTER=spark://spark-master:7077"
- "constraint:node==spark-master"
The spark-master container is listening on three ports:
- Port
8080is exposed so we can see the web frontend of the Apache Spark-Master Dashboard. - Port
7070is used for internal communications.
The spark-worker-1 container is listening on one port:
- Port
9001is exposed, therefore that the installation can receive context data subscriptions. - Ports
8081is exposed, therefore we can see the web frontend of the Apache Spark-Worker-1 Dashboard.
Start Up
Before you start, you should ensure that you have obtained or built the necessary Docker images locally. Please clone the repository and create the necessary images by running the commands shown below. Note that you might need to run some commands as a privileged user:
#!/bin/bash
git clone https://github.com/FIWARE/tutorials.Big-Data-Spark.git
cd tutorials.Big-Data-Spark
git checkout NGSI-LD
./services create
This command will also import seed data from the previous tutorials and provision the dummy IoT sensors on startup.
To start the system with your preferred context broker, run the following command:
./services [orion|scorpio|stellio]
Note: If you want to clean up and start over again you can do so with the following command:
./services stop
Real-time Processing Operations
According to the Apache Spark documentation, Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from many sources like Kafka, Flume, Kinesis, or TCP sockets, and can be processed using complex algorithms expressed with high-level functions like map, reduce, join and window. Finally, processed data can be pushed out to filesystems, databases, and live dashboards. In fact, you can apply Spark’s machine learning and graph processing algorithms on data streams.

Internally, it works as follows. Spark Streaming receives live input data streams and divides the data into batches, which are then processed by the Spark engine to generate the final stream of results in batches.

This means that to create a streaming data flow we must supply the following:
- A mechanism for reading Context data as a Source Operator.
- Business logic to define the transform operations.
- A mechanism for pushing Context data back to the context broker as a Sink Operator.
The Cosmos Spark connector - orion.spark.connector-1.2.2.jar offers both Source and Sink operators. It
therefore only remains to write the necessary Scala code to connect the streaming dataflow pipeline operations together.
The processing code can be complied into a JAR file which can be uploaded to the spark cluster. Two examples will be
detailed below, all the source code for this tutorial can be found within the
cosmos-examples
directory.
Further Spark processing examples can be found on Spark Connector Examples.
Compiling a JAR file for Spark
An existing pom.xml file has been created which holds the necessary prerequisites to build the examples JAR file.
In order to use the Orion Spark Connector we first need to manually install the connector JAR as an artifact using Maven:
cd cosmos-examples
curl -LO https://github.com/ging/fiware-cosmos-orion-spark-connector/releases/download/FIWARE_7.9.1/orion.spark.connector-1.2.2.jar
mvn install:install-file \
-Dfile=./orion.spark.connector-1.2.2.jar \
-DgroupId=org.fiware.cosmos \
-DartifactId=orion.spark.connector \
-Dversion=1.2.2 \
-Dpackaging=jar
Thereafter, the source code can be compiled by running the mvn package command within the same directory
(cosmos-examples):
mvn package
A new JAR file called cosmos-examples-1.2.2.jar will be created within the cosmos-examples/target directory.
Generating a stream of Context Data
For the purpose of this tutorial, we must be monitoring a system in which the context is periodically being updated. The
dummy IoT Sensors can be used to do this. Open the device monitor page at http://localhost:3000/device/monitor and
start a tractor moving. This can be done by selecting an appropriate the command from the drop-down list and pressing
the send button. The stream of measurements coming from the devices can then be seen on the same page:

Logger - Reading Context Data Streams
The first example makes use of the OrionReceiver operator in order to receive notifications from the Orion Context
Broker. Specifically, the example counts the number notifications that each type of device sends in one minute. You can
find the source code of the example in
org/fiware/cosmos/tutorial/Logger.scala.
Logger - Installing the JAR
Restart the containers if necessary, then access the worker container:
docker exec -it spark-worker-1 bin/bash
And run the following command to run the generated JAR package in the Spark cluster:
/spark/bin/spark-submit \
--class org.fiware.cosmos.tutorial.LoggerLD \
--master spark://spark-master:7077 \
--deploy-mode client /home/cosmos-examples/target/cosmos-examples-1.2.2.jar \
--conf "spark.driver.extraJavaOptions=-Dlog4jspark.root.logger=WARN,console"
Logger - Subscribing to context changes
Once a dynamic context system is up and running (we have deployed the Logger job in the Spark cluster), we need to
inform Spark of changes in context.
This is done by making a POST request to the /ngsi-ld/v1/subscriptions endpoint of the Orion Context Broker:
-
The
NGSILD-Tenantheader is used to filter the subscription to only listen to measurements from the attached IoT Sensors, since they had been provisioned using these settings. -
The notification
urimust match the one our Spark program is listening to. -
The
throttlingvalue defines the rate that changes are sampled.
Open another terminal and run the following command:
1 Request:
curl -L -X POST \
'http://localhost:1026/ngsi-ld/v1/subscriptions/' \
-H 'Content-Type: application/ld+json' \
-H 'NGSILD-Tenant: openiot' \
--data-raw '{
"description": "Notify Spark of all animal and farm vehicle movements",
"type": "Subscription",
"entities": [{"type": "Tractor"}, {"type": "Device"}],
"watchedAttributes": ["location"],
"notification": {
"attributes": ["location"],
"format": "normalized",
"endpoint": {
"uri": "http://spark-worker-1:9001",
"accept": "application/json"
}
},
"@context": "http://context/user-context.jsonld"
}'
The response will be 201 - Created.
If a subscription has been created, we can check to see if it is firing by making a GET request to the
/ngsi-ld/v1/subscriptions/ endpoint.
2 Request:
curl -X GET \
'http://localhost:1026/ngsi-ld/v1/subscriptions/' \
-H 'Link: <http://context/user-context.jsonld>; rel="http://www.w3.org/ns/json-ld#context"; type="application/ld+json"' \
-H 'NGSILD-Tenant: openiot'
Response:
Tip: Use jq to format the JSON responses in this tutorial. Pipe the result by appending
| jq '.'
[
{
"id": "urn:ngsi-ld:Subscription:60216f404dae3a1f22b705e6",
"type": "Subscription",
"description": "Notify Spark of all animal and farm vehicle movements",
"entities": [{ "type": "Tractor" }, { "type": "Device" }],
"watchedAttributes": ["location"],
"notification": {
"attributes": ["location"],
"format": "normalized",
"endpoint": {
"uri": "http://spark-worker-1:9001",
"accept": "application/json"
},
"timesSent": 74,
"lastNotification": "2021-02-08T17:06:06.043Z"
}
}
]
Within the notification section of the response, you can see several additional attributes which describe the health
of the subscription.
If the criteria of the subscription have been met, timesSent should be greater than 0. A zero value would indicate
that the subject of the subscription is incorrect or the subscription has created with the wrong fiware-service-path
or fiware-service header.
The lastNotification should be a recent timestamp - if this is not the case, then the devices are not regularly
sending data. Remember to activate the smart farm by moving a Tractor.
The lastSuccess should match the lastNotification date - if this is not the case then Cosmos is not receiving
the subscription properly. Check that the hostname and port are correct.
Finally, check that the status of the subscription is active - an expired subscription will not fire.
Logger - Checking the Output
Leave the subscription running for one minute. Then, the output on the console on which you ran the Spark job will be like the following:
Sensor(Tractor,19)
Sensor(Device,49)
Logger - Analyzing the Code
package org.fiware.cosmos.tutorial
import org.apache.spark._
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.fiware.cosmos.orion.spark.connector._
/**
* Logger example NGSILD Connector
* @author @Javierlj
*/
object LoggerLD{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Example 1")
val ssc = new StreamingContext(conf, Seconds(60))
// Create Orion Receiver. Receive notifications on port 9001
val eventStream = ssc.receiverStream(new NGSILDReceiver(9001))
// Process event stream
eventStream
.flatMap(event => event.entities)
.map(ent => {
new Sensor(ent.`type`)
})
.countByValue()
.window(Seconds(60))
.print()
ssc.start()
ssc.awaitTermination()
}
case class Sensor(device: String)
}
The first lines of the program are aimed at importing the necessary dependencies, including the connector. The next step
is to create an instance of the NGSILDReceiver using the class provided by the connector and to add it to the
environment provided by Spark.
The NGSILDReceiver constructor accepts a port number (9001) as a parameter. This port is used to listen to the
subscription notifications coming from Orion and converted to a DataStream of NgsiEvent objects. The definition of
these objects can be found within the
Orion-Spark Connector documentation.
The stream processing consists of five separate steps. The first step (flatMap()) is performed in order to put
together the entity objects of all the NGSI Events received in a period of time. Thereafter, the code iterates over them
(with the map() operation) and extracts the desired attributes. In this case, we are interested in the sensor type
(Device or Tractor).
Within each iteration, we create a custom object with the property we need: the sensor type. For this purpose, we can
define a case class as shown:
case class Sensor(device: String)
Thereafter, can count the created objects by the type of device (countByValue()) and perform operations such as
window() on them.
After the processing, the results are output to the console:
processedDataStream.print()
Feedback Loop - Persisting Context Data
The second example turns on a water faucet when the soil humidity is too low and turns it back off it when the soil humidity it is back to normal levels. This way, the soil humidity is always kept at an adequate level.
The dataflow stream uses the NGSILDSource operator in order to receive notifications and filters the input to only
respond to motion sensors and then uses the NGSILDSink to push processed context back to the Context Broker. You can
find the source code of the example in
org/fiware/cosmos/tutorial/FeedbackLD.scala.
Feedback Loop - Installing the JAR
/spark/bin/spark-submit \
--class org.fiware.cosmos.tutorial.FeedbackLD \
--master spark://spark-master:7077 \
--deploy-mode client /home/cosmos-examples/target/cosmos-examples-1.2.2.jar \
--conf "spark.driver.extraJavaOptions=-Dlog4jspark.root.logger=WARN,console"
Feedback Loop - Subscribing to context changes
A new subscription needs to be set up to run this example. The subscription is listening to changes of context on the soil humidity sensor.
3 Request:
curl -L -X POST \
'http://localhost:1026/ngsi-ld/v1/subscriptions/' \
-H 'Content-Type: application/ld+json' \
-H 'NGSILD-Tenant: openiot' \
--data-raw '{
"description": "Notify Spark of changes of Soil Humidity",
"type": "Subscription",
"entities": [{"type": "SoilSensor"}],
"watchedAttributes": ["humidity"],
"notification": {
"attributes": ["humidity"],
"format": "normalized",
"endpoint": {
"uri": "http://spark-worker-1:9001",
"accept": "application/json"
}
},
"@context": "http://context/user-context.jsonld"
}'
If a subscription has been created, we can check to see if it is firing by making a GET request to the
/ngsi-ld/v1/subscriptions/ endpoint.
4 Request:
curl -X GET \
'http://localhost:1026/ngsi-ld/v1/subscriptions/' \
-H 'Link: <http://context/user-context.jsonld>; rel="http://www.w3.org/ns/json-ld#context"; type="application/ld+json"' \
-H 'NGSILD-Tenant: openiot'
Feedback Loop - Checking the Output
Go to http://localhost:3000/device/monitor
Raise the temperature in Farm001 and wait until the humidity value is below 35, then the water faucet will be automatically turned on to increase the soil humidity. When the humidity rises above 50, the water faucet will be turned off automatically as well.
Feedback Loop - Analyzing the Code
package org.fiware.cosmos.tutorial
import org.apache.spark._
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.fiware.cosmos.orion.spark.connector._
/**
* FeedbackLD Example Orion Connector
* @author @sonsoleslp
*/
object FeedbackLD {
final val CONTENT_TYPE = ContentType.JSON
final val METHOD = HTTPMethod.PATCH
final val CONTENT = "{\n \"type\" : \"Property\",\n \"value\" : \" \" \n}"
final val HEADERS = Map(
"NGSILD-Tenant" -> "openiot",
"Link" -> "<http://context/user-context.jsonld>; rel=\"http://www.w3.org/ns/json-ld#context\"; type=\"application/ld+json\""
)
final val LOW_THRESHOLD = 35
final val HIGH_THRESHOLD = 50
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Feedback")
val ssc = new StreamingContext(conf, Seconds(10))
// Create Orion Receiver. Receive notifications on port 9001
val eventStream = ssc.receiverStream(new NGSILDReceiver(9001))
// Process event stream
val processedDataStream = eventStream.flatMap(event => event.entities)
.filter(ent => ent.`type` == "SoilSensor")
/* High humidity */
val highHumidity = processedDataStream
.filter(ent => (ent.attrs("humidity") != null) && (ent.attrs("humidity")("value").asInstanceOf[BigInt] > HIGH_THRESHOLD))
.map(ent => (ent.id,ent.attrs("humidity")("value")))
val highSinkStream= highHumidity.map(sensor => {
OrionSinkObject(CONTENT,"http://orion:1026/ngsi-ld/v1/entities/urn:ngsi-ld:Device:water"+sensor._1.takeRight(3)+"/attrs/off",CONTENT_TYPE,METHOD,HEADERS)
})
highHumidity.map(sensor => "Sensor" + sensor._1 + " has detected a humidity level above " + HIGH_THRESHOLD + ". Turning off water faucet!").print()
OrionSink.addSink( highSinkStream )
/* Low humidity */
val lowHumidity = processedDataStream
.filter(ent => (ent.attrs("humidity") != null) && (ent.attrs("humidity")("value").asInstanceOf[BigInt] < LOW_THRESHOLD))
.map(ent => (ent.id,ent.attrs("humidity")("value")))
val lowSinkStream= lowHumidity.map(sensor => {
OrionSinkObject(CONTENT,"http://orion:1026/ngsi-ld/v1/entities/urn:ngsi-ld:Device:water"+sensor._1.takeRight(3)+"/attrs/on",CONTENT_TYPE,METHOD,HEADERS)
})
lowHumidity.map(sensor => "Sensor" + sensor._1 + " has detected a humidity level below " + LOW_THRESHOLD + ". Turning on water faucet!").print()
OrionSink.addSink( lowSinkStream )
ssc.start()
ssc.awaitTermination()
}
}
As you can see, it is similar to the previous example. The main difference is that it writes the processed data back in
the Context Broker through the OrionSink.
The arguments of the OrionSinkObject are:
- Message:
"{\n \"type\" : \"Property\",\n \"value\" : \" \" \n}". - URL:
"http://orion:1026/ngsi-ld/v1/entities/urn:ngsi-ld:Device:water"+sensor._1.takeRight(3)+"/attrs/on"or"http://orion:1026/ngsi-ld/v1/entities/urn:ngsi-ld:Device:water"+sensor._1.takeRight(3)+"/attrs/off", depending on whether we are turning on or off the water faucet. TakeRight(3) gets the number of the sensor, for example '001'. - Content Type:
ContentType.JSON. - HTTP Method:
HTTPMethod.PATCH. - Headers:
Map("NGSILD-Tenant" -> "openiot", "Link" -> "<http://context/user-context.jsonld>; rel=\"http://www.w3.org/ns/json-ld#context\"; type=\"application/ld+json\"" ). We add the headers we need in the HTTP Request.
Next Steps
If you would rather use Flink as your data processing engine, we have this tutorial available for Flink as well.
The operations performed on data in this tutorial were very simple. If you would like to know how to set up a scenario for performing real-time predictions using Machine Learning check out the demo presented at the FIWARE Global Summit in Berlin (2019).
If you want to learn how to add more complexity to your application by adding advanced features, you can find out by reading the other tutorials in this series.