
![]()
![]()
Description This tutorial introduces basics of common Linked Data concepts and Data Models for NGSI-LD developers. The aim is to design and create a simple interoperable Smart Agricultural Solution from scratch and explain how to apply these concepts to your own smart solutions.
Unlike the previous tutorials series, this series will take an NGSI-LD first approach and therefore starts with reiterating the fundamentals of Linked Data and its application to the NGSI-LD interface.
The tutorial is mainly concerned with online and command-line tooling.
![]()
Understanding @context
"The discovery of agriculture was the first big step toward a civilized life."
— Arthur Keith
Creating an interoperable system of readable links for computers requires the use of a well-defined data format (JSON-LD) and assignation of unique IDs (URLs or URNs) for both data entities and the relationships between entities so that semantic meaning can be programmatically retrieved from the data itself. Furthermore, the use and creation of these unique IDs should, as far as possible, be passed around so as not get in the way of the processing the data objects themselves.
An attempt to solve this interoperability problem has been made within the JSON domain, and this has been done by adding
an @context element to existing JSON data structures. This has led to the creation of the JSON-LD standard.
The main takeaway from JSON-LD, is that a remote context file and the JSON-LD
@context definition can be used to assign unique long URIs for
every defined attribute. Developers are then free to use their own regular short attribute names within their own
applications, converting from URIs to preferred shortnames though the application of Expansion and Compaction
operations.
NGSI-LD is a formally structured extended subset of JSON-LD. To promote interoperability, the NGSI-LD API
is defined using the JSON-LD specification and therefore a thorough knowledge of JSON-LD and in particular
@context files is fundamental to the use NGSI-LD.
What is JSON-LD?
JSON-LD is an extension of JSON , it is a standard way of avoiding ambiguity when expressing linked data in JSON so
that the data is structured in a format which is parsable by machines. It is a method of ensuring that all data
attributes can be easily compared when coming from a multitude of separate data sources, which could have a different
idea as to what each attribute means. For example, when two data entities have a name attribute how can the computer
be certain that is refers to a "Name of a thing" in the same sense (rather than a Username or a Surname or
something). URIs and data models are used to remove ambiguity by allowing attributes to have a both short form (such as
name) and a fully specified long form (such http://schema.org/name) which means it is easy to discover which
attribute have a common meaning within a data structure.
JSON-LD introduces the concept of the @context element which provides additional information allowing the computer to
interpret the rest of the data with more clarity and depth.
Furthermore the JSON-LD specification enables you to define a unique @type associating a well-defined
data model to the data itself.
Video: What is Linked Data?
![]()
Click on the image above to watch an introductory video on linked data concepts
Video: What is JSON-LD?
![]()
Click on the image above to watch a video describing the basic concepts behind JSON-LD.
Start Up
Please clone the repository and create the necessary images by running the commands as shown:
git clone https://github.com/FIWARE/tutorials.Understanding-At-Context.git
cd tutorials.Understanding-At-Context
git checkout NGSI-LD
In order to initialize the generator tool run:
./services create
Creating NGSI-LD Data Models
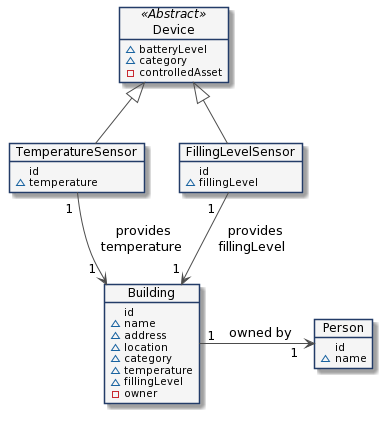
Within the FIWARE platform, every entity represents the state of a physical or conceptual object. Each entity provides the digital twin of an object which exists in the real world.
Although each data entity within your context will vary according to your use case, the common structure within each
data entity should be standardized order to promote reuse. The Fundamentals for FIWARE Data Model design do not change.
Typically, each entity will consist of an id, a type, a series of Property attributes representing context data
which changes over time and a series of Relationship attributes which represent connections between existing
entities.
It is perhaps best to illustrate this using an example. The Underlying Data Models can be created using many tools, however this example will use Swagger schema objects defined using the Open API 3 Standard. The examples are valid Swagger specifications, but in reality, we are not interested in defining in paths and operations, as these are already defined using the NGSI-LD API
The Scenario
Consider the following Smart Agricultural Scenario:
Imagine a farmer owns a barn. The barn contains two IoT devices - a temperature sensor and a filling level sensor indicating how much hay is currently stored in the barn
This example can be split down into the following Entities:
- Building: The barn
- Person: The farmer
- IoT Devices:
- Temperature Senor
- Filling Level Sensor
Baseline Data Models
When architecting your Smart System, it is unnecessary to start from scratch, so the first step is to check to see if there are any existing NGSI-LD data models which are capable of describing your system. As it happens, there are existing Smart Data Models for both Building and Device, so it is possible to check if these will fulfill our needs:
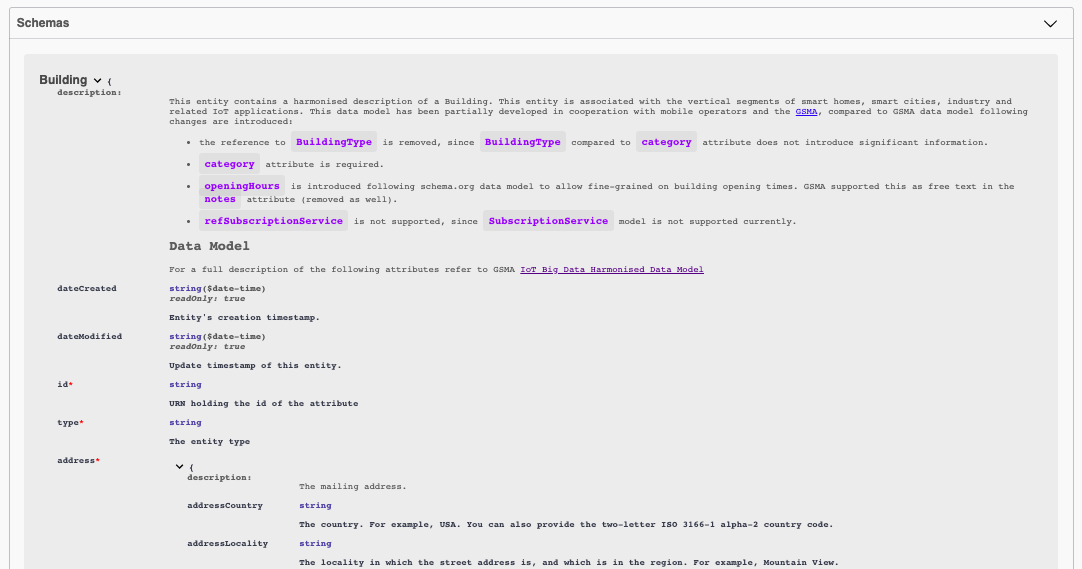
Many common concepts such as Person or Product have been formalized by Schema.org, which is a collaborative community activity for promoting schemas for structured data on the Internet. The schema.org Person can be described using a JSON-LD schema, and may be co-opted as an NGSI-LD data model.
- The Person Data Model can be inspected here
It should be noted that definitions of the models examined so far are very general and will need further modifications
to be of use in a working system, however using these models as the basis of interoperability will ensure that the
resulting @context file will be understandable to the widest number of systems.
Note: The Data Models used here for
@contextgeneration are defined using OpenAPI 3.0 Swagger format. To help with the generation of IRIs the specification has been extended with additional annotations as necessary. Thex-ngsiattribute, as the name suggests is just a simple Specification Extension - usually it is not relevant to Swagger, and indeed you could generate a simple@contextfile without it, but the data held within in has been used to help generate a rich@graphand more comprehensive documentation.Caution: The simple NGSI-LD
@contextgenerator in the tutorial defaults to usinguri.fiware.orgnamespaces and updates with corrected URIs based on thex-ngsi.uriandx-ngsi.uri-prefixattributes. The code and defaults found within this tutorial should be altered to a more widely recognised standard ontology provider within your domain as necessary for your use case.For more complex scenarios, additional
@contextgeneration tools can be found on the Smart Data Models website.
Amending Models
The base data models are useful as a starting point but some enumerated values or attributes will be redundant other required fields will be missing. The base models will therefore need to be modified to create proper digital twins specific to the scenario we are modelling
Removing Redundant Items
Many attributes within data models are optional, and not all options will be valid for our scenario. Take for example,
the category attribute within the Building model - this offers over 60 types of building useful in multiple
domains such as Smart Cities and Smart Agriculture, it is therefore safe to exclude certain options from our own
@context file since they are unlikely to be used. For example a Building categorised as cathedral is unlikely to
be found on a farm.
It is logical to remove bloat before committing to using a particular model as it will help reduce the size of payloads used.
Extending
Looking at the Building model, it is obvious that we will need a Building entity of category="barn", however
the base Building model does not offer additional attributes such as temperature or fillingLevel - these would
need to be added to the base Building so that the context broker is able to hold the context - i.e. the current
state of the building.
Many types of device reading (i.e. context data attributes) have been predefined within the SAREF ontology - so it is reasonable to use the URIs defining these attributes as a basis of extending our model.
temperature(https://w3id.org/saref#temperature)fillingLevel(https://w3id.org/saref#fillingLevel)
Many measurement attributes are defined within the SAREF ontology, but other
ontologies could equally be used. For example, the
iotschema.org schema contains equivalent
term URIs like http://iotschema.org/temperature which could also be used here, the additional data can be added to the
@graph to show the equivalence of the two using Simple Knowledge Organization System terms
SKOS.
Adding metadata
The key goal in designing NGSI-LD data models (as opposed to a generic hierarchy of ontologies), is that wherever possible, every Property attribute of a model represents the context data for a digital twin of something tangible in the real world.
This formulation discourages deep nested hierarchies. A Building has a temperature, a Building has a fillingLevel - anything else is defined as a Relationship - a Building has an owner which links the Building entity to a separate Person entity.
However, just holding the values of properties is insufficient. Saying that temperature=6 is meaningless unless you
also obtain certain metadata, such as When was the reading taken? Which device made the reading? What units are it
measured in? How accurate is the device? and so on.
Therefore, supplementary metadata items will be necessary to ensure that the context data is understandable. This will mean we will need things such as:
- The Units of measurement
- Which sensor provided the measurement
- When was the measurement taken
- and so on.
[
{
"temperature": {
"type": "Property",
"value": 30,
"unitCode": "CEL",
"providedBy": "urn:ngsi-ld:TemperatureSensor:001",
"observedAt": "2016-03-15T11:00:00.000"
}
},
{
"fillingLevel": {
"type": "Property",
"value": 0.5,
"unitCode": "P1",
"providedBy": "urn:ngsi-ld:FillingLevelSensor:001",
"observedAt": "2016-03-15T11:00:00.000"
}
}
]
Each one of these attributes has a name, and therefore requires a definition within the @context. Fortunately most of
these are predefined in the core NGSI-LD specification:
unitCodeis specified from a common list such as the UN/CEFACT List of measurement codesobservedAtis a DateTime a well-defined temporal property expressed in UTC, using the ISO 8601 format.providedByis an example recommendation within the NGSI-LD specification.
Subclassing
As well as extending models by adding new attributes, it is also possible to extend models by subclassing. Looking at
the Device model, it can be seen that whereas common definitions useful to all IoT device such as batteryLevel are
defined in the model, there are no additional attributes within the model explaining which readings are being made.
It would be possible to continue to use the Device model and to add both temperature and fillingLevel, but it is
highly unlikely that a filling sensor would also provide temperatures and vice-versa. In this case, it is therefore
preferred to create a new subclass so that temperature sensors can be considered a different type of entity to filling
sensors.
Using Swagger to extend the Baseline data models
Initial Baseline data models
The following models are defined within the Smart Data Models domain.
components:
schemas:
# This is the base definition of a building
Building:
$ref: "https://fiware.github.io/tutorials.NGSI-LD/models/building.yaml#/Building"
# This is all of the defined building categories
# within the Smart Cities and Smart AgriFood domain
BuildingCategory:
$ref: "https://fiware.github.io/tutorials.NGSI-LD/models/building.yaml#/Categories"
# This is a base definition of an IoT Device
Device:
$ref: "https://fiware.github.io/tutorials.NGSI-LD/models/device.yaml#/Device"
# This is the full list of IoT Device Categories
DeviceCategory:
$ref: "https://fiware.github.io/tutorials.NGSI-LD/models/saref-terms.yaml#/Categories"
# This is a full list of context attributes measurable by devices
ControlledProperties:
$ref: "https://fiware.github.io/tutorials.NGSI-LD/models/saref-terms.yaml#/ControlledProperties"
# This is an NGSI-LD definition of a person.
# Since the schema.org Person is JSON-LD,
# additional type and id attreibutes are require
Person:
allOf:
- $ref: "https://fiware.github.io/tutorials.NGSI-LD/models/ngsi-ld.yaml#/Common"
- $ref: "https://fiware.github.io/tutorials.NGSI-LD/models/schema.org.yaml#/Person"
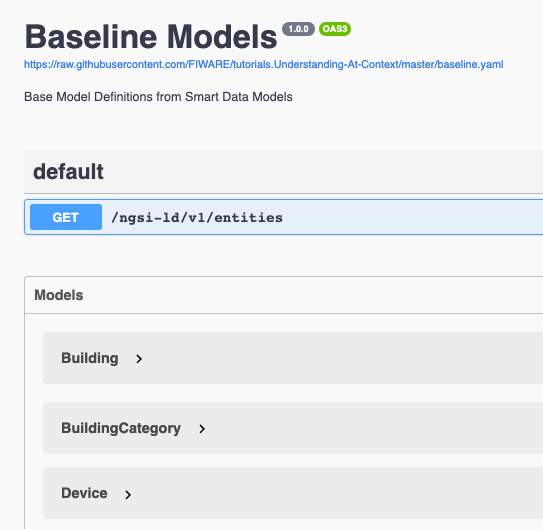
The baseline Data Model can be inspected here.
The source file for the Baseline Date Models, baseline.yaml can be found
here.
Updated Data models
- Building must be updated to accommodate
temperatureandfillingLevel. Both of these properties have been defined within SAREF terms.
Building:
allOf:
- $ref: "https://fiware.github.io/tutorials.NGSI-LD/models/building.yaml#/Building"
properties:
temperature:
$ref: https://fiware.github.io/tutorials.NGSI-LD/models/saref-terms.yaml#/temperature
fillingLevel:
$ref: https://fiware.github.io/tutorials.NGSI-LD/models/saref-terms.yaml#/fillingLevel
-
The list of defined building categories can be reduced to items found within the Agricultural domain (e.g.
barn,cowshed,farm,farm_auxiliary,greenhouse,riding_hall,shed,stable,sty,water_tower) -
The base Device can be removed and replaced with two new models which extend it -
TemperatureSensorandFillingLevelSensor. Once again these add additional SAREF terms to the baseDeviceclass.
TemperatureSensor:
type: object
required:
- temperature
allOf:
- $ref: https://fiware.github.io/tutorials.NGSI-LD/models/device.yaml#/Device
properties:
temperature:
$ref: https://fiware.github.io/tutorials.NGSI-LD/models/saref-terms.yaml#/temperature
FillingLevelSensor:
type: object
required:
- FillingLevelSensor
allOf:
- $ref: https://fiware.github.io/tutorials.NGSI-LD/models/device.yaml#/Device
properties:
fillingLevel:
$ref: https://fiware.github.io/tutorials.NGSI-LD/models/saref-terms.yaml#/fillingLevel
-
The list of controlled attributes can be reduced to those measured by Agricultural devices (e.g
depth,eatingActivity,humidity,location,milking,motion,movementActivity,occupancy,precipitation,pressure,soilMoisture,solarRadiation,temperature,waterConsumption,weatherConditions,weight,windDirection,windSpeed) -
The other definitions remain unchanged.
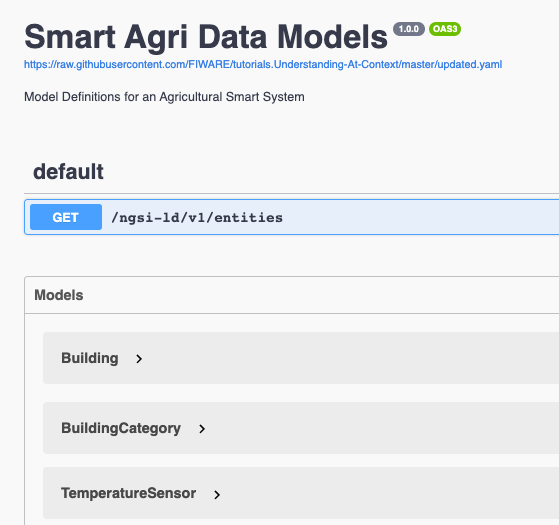
The updated Data Models for an Agricultural Smart System can be inspected here.
The raw source file agriculture.yaml can be found
here
Auto generating @Context Files from Swagger
Every working linked data system relies on @context files to supply the relevant information about the data. Creating
such files by hand is a tedious and error-prone procedure, so it makes sense to automate the process. The required
structure will depend on the operations involved.
This tutorial will take the Agricultural Smart System data model file agriculture.yaml and autogenerate alternatives
for use by other agents.
A deeper understanding can be obtained by running this tutorial with a more advanced example, the equivalent Data Models from the Supermarket Scenario have also been added to this tutorial. The raw
supermarket.yamlfile is available here
Validating a Swagger Data Models
It is necessary to check that the model is valid before processing, this can be done by viewing it online or by using a simple validator tool.
./services validate [file]
Terminal - Result:
The API is valid
The underlying file(s) are a valid Swagger definition which ensures that the tool can be used to extract attributes and enumerations as necessary.
Generating an NGSI-LD @context file
The NGSI-LD @context needs to hold defined URIs for the following:
- The defined entity
typeswithin the system - The names of all the attributes from within the defined Data Models
- The names of all the metadata attribute from within the Data Models
- The enumerated values of any constants used within the Data Models.
An NGSI-LD @context file can be generated from a Swagger data model as follows:
./services ngsi [file]
Terminal - Result:
Creating a NGSI-LD @context file for normalized interactions
datamodels.context-ngsi.jsonld created
Opening the generated file, the following structure can be found:
{
"@context": {
"type": "@type",
"id": "@id",
"ngsi-ld": "https://uri.etsi.org/ngsi-ld/",
"fiware": "https://uri.fiware.org/ns/dataModels#",
"schema": "https://schema.org/",
...etc
"Building": "fiware:Building",
"FillingLevelSensor": "fiware:FillingLevelSensor",
"Person": "fiware:Person",
"TemperatureSensor": "fiware:TemperatureSensor",
... etc
"actuator": "https://w3id.org/saref#actuator",
"additionalName": "schema:additionalName",
"address": "schema:address",
"barn": "https://wiki.openstreetmap.org/wiki/Tag:building%3Dbarn",
"batteryLevel": "fiware:batteryLevel",
"category": "fiware:category",
"configuration": "fiware:configuration",
"conservatory": "https://wiki.openstreetmap.org/wiki/Tag:building%3Dconservatory",
"containedInPlace": "fiware:containedInPlace",
"controlledAsset": "fiware:controlledAsset",
"controlledProperty": "fiware:controlledProperty",
"cowshed": "https://wiki.openstreetmap.org/wiki/Tag:building%3Dcowshed",
"depth": "https://w3id.org/saref#depth",
...etc
}
}
The resultant @context file is a valid JSON-LD Context file usable by NGSI-LD
applications. The file is structured into three parts:
- A list of standard terms and abbreviations - this avoids the necessity of repeating URIs and reduced the overall size of the file
- A series of defined entity types (e.g.
Building). These usually start with a capital letter. - A list of attributes (e.g.
address) and enumerations (e.g.barn)
Effectively this NGSI-LD @context can be combined with a copy of the NGSI-LD core context
https://uri.etsi.org/ngsi-ld/v1/ngsi-ld-core-context-v1.8.jsonld
to mechanically define the following:
If a computer encounters an entity of type=Building this really refers to a
https://uri.fiware.org/ns/dataModels#Building
From the definition of a Building we know it has a mandatory category and address.
If a computer encounters an address attribute, this really refers to a https://schema.org/address (which in turn has
well-defined sub-attributes)
If a computer encounters a category=barn then it should be possible to ensure that this category can be identified
as a https://wiki.openstreetmap.org/wiki/Tag:building%3Dbarn. Note that category itself is also well-defined.
NGSI-LD @contexts are used for all NGSI-LD CRUD operations, and are required when sending or receiving NGSI-LD data in
the default normalized format. The normalized format includes a structure of attributes each with its own type and
value
For example this is a Building in normalized NGSI-LD format:
{
"id": "urn:ngsi-ld:Building:001",
"type": "Building",
"category": {
"type": "VocabProperty",
"vocab": "barn"
},
"address": {
"type": "Property",
"value": {
"streetAddress": "Großer Stern",
"addressRegion": "Berlin",
"addressLocality": "Tiergarten",
"postalCode": "10557"
}
},
"location": {
"type": "GeoProperty",
"value": {
"type": "Point",
"coordinates": [13.35, 52.5144]
}
},
"name": {
"type": "Property",
"value": "Siegessäule Barn"
},
"@context": [
"https://example.com/data-models.context-ngsild.jsonld",
"https://uri.etsi.org/ngsi-ld/v1/ngsi-ld-core-context-v1.8.jsonld"
]
}
The core context file defines the base structure of the NGSI-LD API payload (things like type, value and GeoJSON
Point) whereas the generated NGSI-LD context for the application itself defines the entities (Building) and
attributes without defining a payload structure.
Generating a JSON-LD @context file
The JSON-LD @context differs from the NGSI-LD @context file as it is standalone and does not use the core context
definitions and does not specify metadata attribute definitions such as properties-of-properties. It is used in
combination with the simplified NSGI-LD key-values pairs payloads.
The JSON-LD requires the following:
- The names of all the attributes from within the defined Data Models
- The enumerated values of any constants used within the Data Models.
Additionally, a JSON-LD @context may also include supplementary information (such as This attribute is an integer)
and, within the @graph definition, information about the relationships between nodes (This attribute is a link to a
Person entity ) as well as human-readable information about the attributes themselves (A barn is an agricultural
building used for storage) may be returned.
An JSON-LD @context file can be generated from a Swagger data model as follows:
./services jsonld [file]
Terminal - Result:
Creating a JSON-LD @context file for key-values interactions
datamodels.context.jsonld created
Opening the generated file, the following structure can be found:
{
"@context": {
"type": "@type",
"id": "@id",
"ngsi-ld": "https://uri.etsi.org/ngsi-ld/",
"fiware": "https://uri.fiware.org/ns/dataModels#",
"schema": "https://schema.org/",
"rdfs": "http://www.w3.org/2000/01/rdf-schema#",
"xsd": "http://www.w3.org/2001/XMLSchema#",
... etc
"Building": "fiware:Building",
"FillingLevelSensor": "fiware:FillingLevelSensor",
... etc
"actuator": "https://w3id.org/saref#actuator",
"additionalName": {
"@id": "schema:additionalName",
"@type": "xsd:string"
},
"address": "schema:address",
"barn": "https://wiki.openstreetmap.org/wiki/Tag:building%3Dbarn",
"controlledAsset": {
"@id": "fiware:controlledAsset",
"@type": "@id"
},
"depth": "https://w3id.org/saref#depth",
... etc
},
"@graph": [
...etc
{
"@id": "fiware:fillingLevel",
"@type": "ngsi-ld:Property",
"rdfs:comment": [
{
"@language": "en",
"@value": "Property related to some measurements that are characterized by a certain value that is a filling level."
}
],
"rdfs:label": [
{
"@language": "en",
"@value": "fillingLevel"
}
]
}
]
}
Once again the resultant @context file is a valid JSON-LD, this time however
it has been designed to be used by any application that understands generic JSON-LD applications. The file is structured
as follows:
- A list of standard terms and abbreviations - this avoids the necessity of repeating URIs and reduced the overall size of the file. For further information read the section on aliasing keywords from the JSON-LD specification.
- A series of defined entity types (e.g.
Building). These usually start with a capital letter. - A list of attributes - these may be subdivided as follows:
- attributes representing context data Properties to be displayed as native JSON attributes (e.g.
additionalName), these attributes are annotated to explain the XML Schema datatype to be used when consuming the data. - attributes representing context data Properties which are complex of objects (e.g.
address), these are remain as in the previous example, there is an indication thataddressreally refers to ahttps://schema.org/address- which in turn has well-defined sub-attributes - and the native types of those sub-elements are also defined. - attributes representing context data Properties which hold enumerations - e.g.
category- these hold a link indicator in the form of"@type": "@vocab". When these attributes are encountered it indicates that the valuecategory="barn"can be expanded to the IRIhttps://wiki.openstreetmap.org/wiki/Tag:building%3Dbarnrather than just as a string holding the short namebarn. For further information on how this is achieved, look at the shortening IRIs in the JSON-LD specification. - attributes representing context data Relationships - e.g.
controlledAsset- these hold an indicator of a link between entities in the form of"@type": "@id". This is the syntax indicating a link, or more formally an Internationalized Resource Identifier (see RFC3987). For further information see the section on IRIs within the JSON-LD specification
- attributes representing context data Properties to be displayed as native JSON attributes (e.g.
- A list of enumerations (e.g.
barn) - these can be readily expanded by the receiving application when held within defined@vocabelements.
Furthermore, an additional section in this context file called the @graph. This enables the JSON-LD @context to make
additional statements about the graph of linked data itself For example, the generated @graph elements are show a
human-readable description of the attribute in English. This could be further expanded to indicate in which entities
each attribute is used, whether an entity definition is a subclass of a base definition (e.g. TemperatureSensor
extends Device) and so on.
Further information about @graph can be found in the section on
Named Graphs.
If NGSI-LD requests are made using the format=simplified parameter, the response a generic JSON-LD object (as shown
below) rather than a full NGSI-LD object:
{
"id": "urn:ngsi-ld:Building:001",
"type": "Building",
"category": "barn",
"address": {
"streetAddress": "Großer Stern",
"addressRegion": "Berlin",
"addressLocality": "Tiergarten",
"postalCode": "10557"
},
"location": {
"type": "Point",
"coordinates": [13.35, 52.5144]
},
"name": "Siegessäule Barn",
"@context": "https://example.com/data-models.context.jsonld"
}
This format should be familiar to any user of JSON - the additional @context attribute is the mechanism used to
annotate the base JSON payload as JSON-LD linked data.
It should be noted that this JSON-LD payload does not include metadata about attributes - there are no properties of
properties or relationships of properties. Therefore, to include a traversable link within JSON-LD it is necessary to
declare it as Relationship directly on the entity itself- an example can be found in the controlledAsset attribute
of Device. Metadata attributes such as the providedBy Relationship found within the temperature Property
are only traversable using the NGSI-LD syntax.
Generating Documentation
The @context syntax is designed to be readable by machines. Obviously developers need human-readable documentation
too.
Basic documentation about NGSI-LD entities can be generated from a Swagger data model as follows:
./services markdown [file]
Terminal - Result:
Creating Documentation for the Data Models
datamodels.md created
The result is a Markdown file holding the documentation for the data models is returned.